Representation Learning with Mutual Information Maximization¶
\(f\)-GAN¶
2016 NIPS - \(f\)-GAN: Training Generative Neural Samplers using Variational Divergence Minimization 1
\(f\)-divergence¶
Suppose we want to train a generative model \(Q\) that generates data as realistic (close to the true data distribution \(P\)) as possible. In other words, we wish to minimize the \(f\)-divergence
where \(f:\R^+ \to \R\) is convex, lower-semicontinuous and satisfies \(f(1) = 0\).
Below is a table of the \(f\)-divergence family.
| Name | \(\Dcal_f(P \Vert Q)\) | \(f(u)\) | \(T^*(u)\) |
|---|---|---|---|
| Total variation | \(\frac{1}{2} \int \vert p(x) - q(x) \vert \dd x\) | \(\frac{1}{2} \vert u - 1 \vert\) | \(\frac{1}{2} \sign (u - 1)\) |
| Kullback-Leibler (KL) | \(\int p(x)\log \frac{p(x)}{q(x)} \dd x\) | \(u \log u\) | \(1+\log u\) |
| Reverse KL | \(\int q(x)\log \frac{q(x)}{p(x)} \dd x\) | \(- \log u\) | \(-\frac{1}{u}\) |
| Pearson \(\chi^2\) | \(\int \frac{(q(x) - p(x))^{2}}{p(x)} \dd x\) | \((1 - u)^{2}\) | \(2(u-1)\) |
| Neyman \(\chi^2\) | \(\int \frac{(p(x) - q(x))^{2}}{q(x)} \dd x\) | \(\frac{(1 - u)^{2}}{u}\) | \(1-\frac{1}{u^2}\) |
| Squared Hellinger | \(\int \left(\sqrt{p(x)} - \sqrt{q(x)}\right)^{2} \dd x\) | \((\sqrt{u} - 1)^{2}\) | \((\sqrt{u}-1)\sqrt{\frac{1}{u}}\) |
| Jeffrey | \(\int (p(x) - q(x))\log \left(\frac{p(x)}{q(x)}\right) \dd x\) | \((u - 1)\log u\) | \(1+\log u - \frac{1}{u}\) |
| Jensen-Shannon | \(\frac{1}{2}\int p(x)\log \frac{2 p(x)}{p(x) + q(x)} + q(x)\log \frac{2 q(x)}{p(x) + q(x)} \dd x\) | \(-\frac{u + 1}{2}\log \frac{1 + u}{2} + \frac{u}{2} \log u\) | \(\frac{1}{2}\log\frac{2u}{u+1}\) |
| \(\alpha\)-divergence | \(\frac{1}{\alpha (\alpha - 1)}\int p(x)\left[ \left(\frac{q(x)}{p(x)}\right)^\alpha - 1 \right] - \alpha(q(x) - p(x)) \dd x\) | \(\frac{1}{\alpha (\alpha - 1)}(u^\alpha - 1 - \alpha(u-1))\) | \(\frac{1}{\alpha - 1}\left( u^{\alpha-1} - 1 \right)\) |
Fenchel conjugate
The Fenchel conjugate of function \(f(x)\) is defined as \(f^*(x^*) = \sup_{x \in \dom f} \big\{ \langle x, x^* \rangle - f(x) \big\}\).
We can easily verify that \(f^*\) is convex and lower-semicontinuous. When \(f\) is also convex and lower semi-continuous, \(f^{**} = f\).
Variational representation of the \(f\)-divergence¶
We now derive the variational lower bound on \(f\)-divergence:
where \(\Tcal\) is a class of functions \(T: \Xcal \to \R\). It is straightforward to see that the optimal \(T^*(x) = f^\prime \left( \frac{p(x)}{q(x)} \right)\) (please do not confuse with conjugate function) by substituting the definition of \(f^*\) and let \(t\) be \(\frac{p(x)}{q(x)}\)
The critical value \(f^\prime(1)\) can be interpreted as a classification threshold applied to \(T(x)\) to distinguish between true and generated samples.
\(f\)-GAN Objective¶
We parameterize the generator \(Q\) with parameter \(\theta\) and the discriminator \(T\) with parameter \(\omega\). The \(f\)-GAN objective is then defined as
To account for \(\dom f^*\) of various \(f\)-divergence, we further decompose \(T_\omega(x)\) into \(T_\omega(x) = g_f\big(V_\omega(x) \big)\), where \(V_\omega: \Xcal \to \R\) is a neural network and \(g_f : \R \to \dom f^*\) is an output activation function.
| Name | \(g_f\) | \(\dom f^*\) | \(f^*(t)\) | \(f^\prime(1)\) |
|---|---|---|---|---|
| Total variation | \(\frac{1}{2}\tanh(v)\) | \(\left[-\frac{1}{2},\frac{1}{2}\right]\) | \(t\) | \(0\) |
| Kullback-Leibler (KL) | \(v\) | \(\R\) | \(\ee^{t-1}\) | \(1\) |
| Reverse KL | \(-\ee^v\) | \(\R_-\) | \(-1 - \log(-t)\) | \(-1\) |
| Pearson \(\chi^2\) | \(v\) | \(\R\) | \(\frac{1}{4}t^2 + t\) | \(0\) |
| Neyman \(\chi^2\) | \(1-\ee^{v}\) | \((-\infty,1)\) | \(2-2\sqrt{1-t}\) | \(0\) |
| Squared Hellinger | \(1-\ee^{v}\) | \((-\infty,1)\) | \(\frac{t}{1-t}\) | \(0\) |
| Jeffery | \(v\) | \(\R\) | \(W(\ee^{1-t})+\frac{1}{W(\ee^{1-t})}+t-2\) | \(0\) |
| Jensen-Shannon | \(\frac{\log 2}{2}-\frac{1}{2}\log(1+\ee^{-v})\) | \(\left(-\infty,\frac{\log 2}{2}\right)\) | \(-\frac{1}{2}\log(2-\ee^{2t})\) | \(0\) |
| \(\alpha\)-div. (\(\alpha \in (0,1)\)) | \(\frac{1}{1-\alpha} - \log(1+\ee^{-v})\) | \((-\infty, \frac{1}{1-\alpha})\) | \(\frac{1}{\alpha}(t(\alpha-1)+1)^{\frac{\alpha}{\alpha-1}} - \frac{1}{\alpha}\) | \(0\) |
| \(\alpha\)-div. (\(1<\alpha\)) | \(v\) | \(\R\) | \(\frac{1}{\alpha}(t(\alpha-1)+1)^{\frac{\alpha}{\alpha-1}} - \frac{1}{\alpha}\) | \(0\) |
where \(W\) is the Lambert-\(W\) product log function.
Mutual Information Neural Estimator (MINE)¶
2018 ICML - MINE: Mutual Information Neural Estimation 2
MINE has two variants termed MINE and MINE-\(f\). The former uses the Donsker-Varadhan representation of the KL divergence, which results in a tighter estimator; the latter uses the \(f\)-divergence representation described above.
The Donsker-Varadhan representation of KL¶
Proof: Consider the Gibbs distribution \(g(x) = \frac{1}{Z} q(x) \ee^{T(x)}\) where \(Z = \E_{q(x)} \ee^{T(x)}\). Then
where \(\Tcal\) is a class of functions \(T: \Xcal \to \R\) such that the two expectations are finite. The equality holds when \(g(x) \equiv p(x)\), i.e. \(T^*(x) = \log \frac{p(x)}{q(x)} + C\).
The \(f\)-divergence representation of KL¶
Adopting the variational lower bound for \(f\)-divergence, we have
and the optimal \(T^*(x) = 1+\log \frac{p(x)}{q(x)}\).
Estimating Mutual Information¶
We estimate the expectations with empirical samples
When using stochastic gradient descent (SGD), the gradient update of MINE
is a biased estimate of the full gradient update (Why?). This is corrected by an exponential moving average applied to the denominator. For MINE-\(f\), the SGD gradient is unbiased.
Contrastive Predictive Coding (CPC) and the InfoNCE Loss¶
2010 AISTATS - Noise-contrastive estimation: A new estimation principle for unnormalized statistical models 3
2018 NeurIPS - Representation Learning with Contrastive Predictive Coding 4
Noise-Contrastive Estimation (NCE)¶
Suppose we have observed data \(\mathbf{x} \sim p_d(\cdot)\) and we want to estimate a model from a family \(\{p_\mathrm{m}(\cdot;\alpha)\}_\alpha\) where \(\alpha\) is the model parameter. The challenge is that often it is more convenient to define an unnormalized model \(p_\mathrm{m}^0\) such that
The integral \(Z(\alpha)\) is rarely analytically tractable, and if the data is highdimensional, numerical integration is difficult. We include the normalization constant \(Z(\alpha)\) as an additional parameter \(c \approx -\log Z(\alpha)\), so that
Performing Maxmimum Likelihood Estimation (MLE) on this objective is not feasible as \(c\) would be pushed to infinity. Instead we learn to discriminate between the data \(\mathbf{x}\) and some artificially generated noise \(\mathbf{y} \sim p_{\mathrm{n}}\). With \(T\) positive (data) and \(T\) negative (noise) examples, we aim to correctly classify each of them, and thus define the NCE objective as
where \(h(\mathbf{u}; \theta) = \sigma\big(\log p_{\mathrm{m}}(\mathbf{u}; \theta) - \log p_{\mathrm{n}}(\mathbf{u}) \big)\).
This blog post (in Chinese) shows by gradient calculation that when the number of negative samples approches infinity, the NCE gradient equals to the MLE gradient.
Contrastive Predictive Coding¶
Let \(\{x_t\}\) be a sequence of observations, \(z_t = g_{\mathrm{enc}}(x_t)\) be the encoded latent representation at time step \(t\), and \(c_t = g_{\mathrm{ar}}(z_{\le t})\) be the summarized context (global, ar for auto-regressive) latent representation at time step \(t\). Given a set \(X = \{x_1, \cdots, x_N\}\) of \(N\) random samples containing one positive sample from \(p(x_{t+k}|c_t)\) and \(N - 1\) negative samples from the 'proposal' distribution \(p(x_{t+k})\), we wish to preserve the mutual information between the \(k\)-step-later input \(x_{t+k}\) and the current context \(c_t\), by trying to identify the positive sample among all the samples:
where \(f_{k}(x_{t+k}, c_t) = C \frac{p(x_{t+k}|c_t)}{p(x_{t+k})}\) and \(C\) is an arbitrary constant. Note that \(f\) is unnormalized and can be parameterized by a simple log-bilinear model
To maximize our contrastive predictive capabilities, we minimize the following InfoNCE loss:
Relation with Mutual Information¶
Proof:
Note that the approximation is more accurate as the number of negative samples increases.
Relation with MINE¶
Let \(F(x, c) = \log f(x, c)\), then
which is equivalent to the MINE estimator:
Deep InfoMax (DIM)¶
2019 ICLR - Learning deep representations by mutual information estimation and maximization 5
Deep InfoMax is a principled framework for training a continuous and (almost everywhere) differentiable encoder \(E_\psi: \Xcal \to \Zcal\) to maximize mutual information between its input and output, with neural network parameters \(\psi \in \Psi\).
Assume that we are given a set of training examples on an input space, \(\mathbf{X} := \{x^{(i)} \in \Xcal\}_{i=1}^N\), with empirical probability distribution \(P\). We define \(U_{\psi,P}\) as the marginal distribution of \(z=E_\psi(x)\) where \(x\) is sampled from \(P\), i.e., \(u(z=E_\psi(x)) = \big( \nabla_x E_\psi(x) \big)^{-1} p(x)\).
We assert our encoder should be trained according to the following criteria:
- Local and global mutual information maximization
- Statistical constraints (prior in the latent space \(v(z)\)).
As a preliminary, we introduce the local feature encoder \(C_\psi\), the global feature encoder \(E_\psi = f_\psi \circ C_\psi\) and the discriminator \(T_{\psi, \omega} = D_\omega \circ g \circ (C_\psi, E_\psi)\), where \(D_\omega\) is a neural classifier, and \(g\) is a function that combines the local and global features.
The overall DIM objective consists of three parts, global MI, local MI and statistical constraints.
In the following sections, we first introduce how to enfore statistical constraints \(\hat{D}_\phi\) and local MI maximization, then discuss objectives for general MI maximization \(\hat{I}\).
Statistical Constraints¶
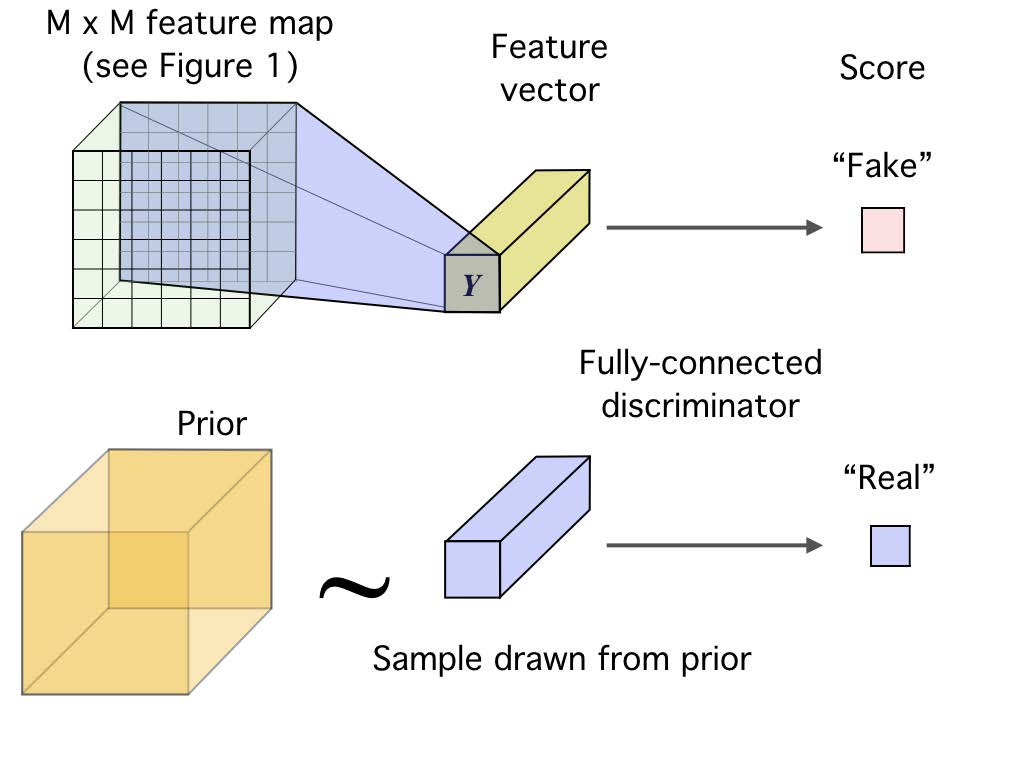
Why use adversarial objectives for KL regularization?
Here we could also use VAE-style prior regularization \(\min \KL \big(q(z|x) \Vert p(z) \big)\), but this assumes for every data point \(x\), its latent \(q(z|x)\) is close to \(p(z)\). This will encourage \(q(z)\) to pick the modes of \(p(z)\), rather than the whole distribution of \(p(z)\). See the Adversarial AutoEncoders paper for more details.
DIM imposes statistical constraints onto learned representations by implicitly training the encoder so that the push-forward distribution, \(U_{\psi, P}\), matches a prior \(V\). Following variational representation of the Jensen-Shannon divergence, we optimize this objective by
Note that the discriminator \(D_\phi\) operates in the latent space rather than the input space.
Local MI Maximization¶
Maximizing the mutual information b/t encoder input and output may not be meaningful enough. We propose to maximize the average MI between the high-level representation and local patches of the image. Because the same global representation is encouraged to have high MI with all the patches, this favours encoding aspects of the data that are shared across patches.
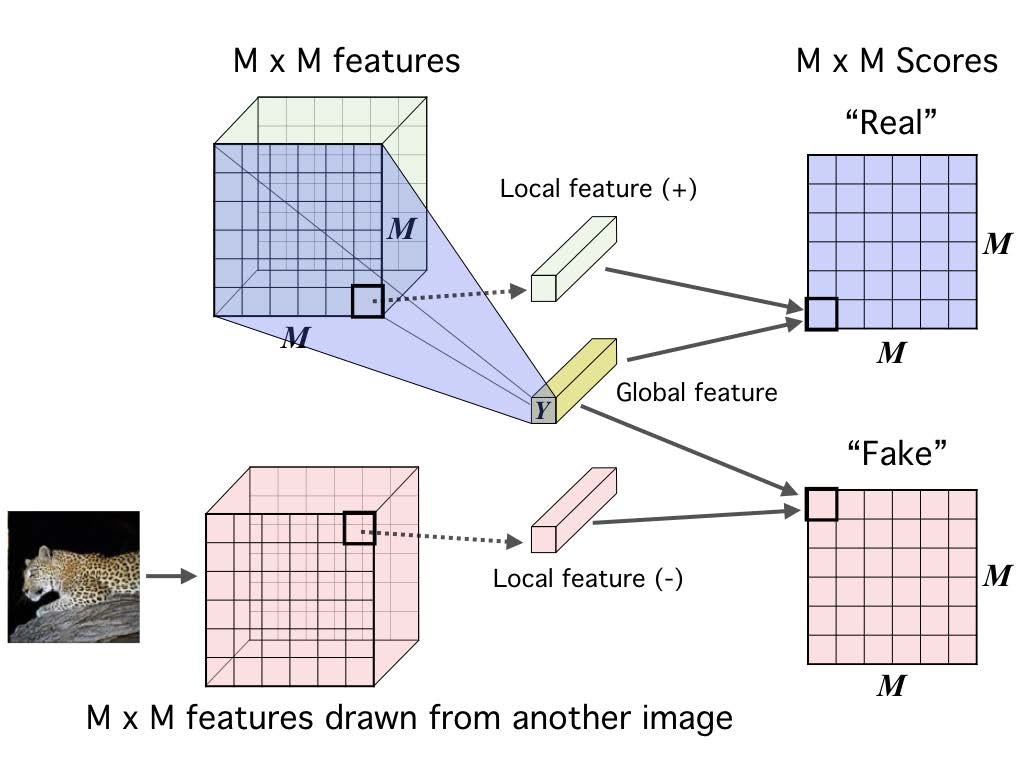
First we encode the input to a feature map, \(C_\psi(x) = \{ C_\psi^{(i)} \}_{i=1}^{M\times M}\) that reflects useful structure in the data (e.g., spatial locality). Next, we summarize this local feature map into a global feature, \(E_\psi(x) = f_\psi \circ C_\psi(x)\). We then define our MI estimator on global/local pairs, maximizing the average estimated MI:
MI Maximization Objectives¶
The Donsker-Varadhan Objective¶
This lower-bound to the MI is based on the Donsker-Varadhan representation of the KL-divergence. It is the tightest possible bound on KL divergence, but it is less stable and requires many negative samples.
The Jensen-Shannon Objective¶
Since we do not concern the precise value of mutual information, and rather primarily interested in its maximization, we could instead optimize on the Jensen-Shannon divergence. This objective is stable to optimize and requires few negative sample, but it is a looser bound to the true mutual information.
Following \(f\)-GAN formulation, with output activation \(g_f = -\log(1+\ee^{-v})\) and conjugate function \(f^*(t) = -\log(1-\ee^t)\), we define the following objective:
where \(\widetilde{T} = g_f \circ T\) is the discriminator output after activation \(g_f\). In section A.1 of the DMI paper 5, the authors show theoretically and empirically that \(\max_{\psi, \omega} \JS(p(x, z) \Vert p(x)p(z))\) is indeed a good maximizer of \(I(X; Z)\).
The InfoNCE Objective¶
This objective uses noise-contrastive estimation to bound mutual information. It obtains strong results, but requires many negative samples.
Deep Graph Infomax¶
2019 ICLR - Deep Graph Infomax 6
Deep Graph Infomax (DGI) is a general approach for learning node representations within graph-structured data in an unsupervised manner. It relies on maximizing mutual information between patch representations and corresponding high-level summaries of graphs.
We first introduce
- The encoder \(E: \R^{N \times F^{\mathrm{in}}} \times \R^{N \times N} \to \R^{N \times F}\) such that \(E(\mathbf{X}, \mathbf{A}) = \mathbf{H} = (\mathbf{h}_1, \dots, \mathbf{h}_N)^\top\) produces node embeddings (or patch representations) that summarize a patch of the graph centered around node \(i\).
- The readout function \(R: \R^{N \times F} \to \R^F\) which summarizes the obtained patch representations into a graph-level representation \(\mathbf{s} = R(E(\mathbf{X}, \mathbf{A}))\). It is implemented as a sigmoid after a mean \(R(\mathbf{H}) = \sigma\left( \frac{1}{N} \sum_{i=1}^N \mathbf{h}_i \right)\).
- The discriminator \(D: \R^F \times \R^F \to \R\) such that \(D(\mathbf{h}_i, \mathbf{s})\) represents the logit scores assigned to this patch-summary pair (should be higher for patches contained within the summary). It is implemented as a bilinear function \(D(\mathbf{h}_i, \mathbf{s}) = \mathbf{h}_i \mathbf{W} \mathbf{s}\).
- Negative samples are generated by pairing the summary vector \(\mathbf{s}\) of a graph with patch representations \(\widetilde{\mathbf{h}}_j\) from another graph \((\widetilde{\mathbf{X}}, \widetilde{\mathbf{A}})\). This alternative graph is obtained as other elements of a training set in a multi-graph setting, or by an explicit corruption function \((\widetilde{\mathbf{X}}, \widetilde{\mathbf{A}}) = C(\mathbf{X}, \mathbf{A})\) which permutes row-wise the node feature matrix \(\mathbf{X}\).
Next we introduce the DGI objective for one training graph \(\Gcal = (\mathbf{X}, \mathbf{A})\), based on the Jensen-Shannon objective for Deep InfoMax
InfoGraph¶
2020 ICLR - InfoGraph: Unsupervised and Semi-supervised Graph-Level Representation Learning via Mutual Information Maximization 7
InfoGraph studies learning the representations of whole graphs (rather than nodes as in DGI) in both unsupervised and semi-supervised scenarios. Its unsupervised version is similar to DGI except for
- Batch-wise generation of negative samples rather than random-sampling- or corruption-based negative samples.
- GIN methodologies for better graph-level representation learning.
In semi-supervised setting, directly adding a supervised loss would likely result in negative transfer. The authors alleviate this problem by separating the parameters of the supervised encoder \(\varphi\) and those of the unsupervised encoder \(\phi\), and adding a student-teacher loss which encourage mutual information maximization between the two encoders at all levels. The overall loss is:
In practice, to reduce the computational overhead, at each training step, we enforce mutual-information maximization on a randomly chosen layer of the encoder.
-
NeurIPS 2016 - \(f\)-GAN: Training Generative Neural Samplers using Variational Divergence Minimization; A blog post explaining the paper in Chinese. ↩
-
ICML 2018 - MINE: Mutual Information Neural Estimation ↩
-
AISTATS 2010 - Noise-contrastive estimation: A new estimation principle for unnormalized statistical models ↩
-
NeurIPS 2018 - Representation Learning with Contrastive Predictive Coding ↩
-
ICLR 2019 - Learning deep representations by mutual information estimation and maximization (slides, video); A blog post explaining the paper in Chinese. ↩↩
-
ICLR 2019 - Deep Graph Infomax. For relations with previous unsupervised graph representation learning methods, see the IPAM tutorial Unsupervised Learning with Graph Neural Networks by Thomas Kipf and also Daza's Master Thesis A Modular Framework for Unsupervised Graph Representation Learning. ↩
-
ICLR 2020 - InfoGraph: Unsupervised and Semi-supervised Graph-Level Representation Learning via Mutual Information Maximization ↩